Data science
1. Юрий Карев (ВТБ).
2. Максим Карпенко (Майл ру)
3. Евгений Лопаткин (Теле 2)
4. Артём Трофимов (Яндекс)
5. Андрей Бедин (ВТБ)
1. В целях масштабирования и совершенствования аналитических решений ведущие игроки используют концепцию MLOps.
1. Цифровой двойник.
2. Big Data технологии.
3. Сервисная модель – MLOps.
Мы решаем бизнес-задачи. Разрабатываем модель с учетом жизненного цикла. Использование DevOps нароботок. Разница между программированием и машинным обучением в том, что в программировании на вход машине подаем алгоритм и данные, машина рассчитывает результат. В машинном обучении мы подаем на вход данные и ожидаем результаты.
DevOps-стек. Репозиторий (модель, витрина, алгоритмы), развертывание (модель, контейнер, библиотеки), автотесты (модель, витрина, скрипты для тестирования, метрики), мониторинг (расписание, дэшборды, алерты), обратная связь (группа реагирования, data engineer, MLOps engineer, data scientist).
Инфраструктура. DEV (субд - программные модули) – > TEST (Синтетические тесты – программные модули – модель М1) – > Данные PROD (ПМ – Модель М1 – Контур разработки моделей)
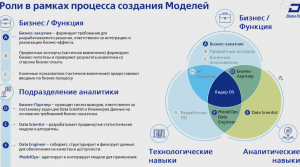
Продуктом, создающим ценность для бизнеса является не только модель но и технологическое решение по ее применению в бизнес процессе. Ключевые цели MLOps – сокращение ТТМ, повышение эффективности команд, масштабируемость. Сервисная модель определяет ключевые комптенеции, участвующие в разработке моделей и типовой процесс взаимодействия между ними.
2. Мифическая воспроизводимость в MLOps.
1. Что такое воспроизводимость. Data Science is not Data Programmnig. Это зачастую итеративный процесс. Важны промежуточные шаги. Прототип – эксперименты – сервис. Воспроизводимость давно обсуждается в исследовательских кругах. Типы воспроизводимости (вычислительная, эмпирическая, статистическая).
2. Инструменты и подходы. MLflow – платформа для управления ML разработкой. Логирование экспериментов, организация кода. Возможности – воспроизводимость экспериментов и применения. DVC – данные сохраняются в хранилище, метаданные версионируются через git. Статистическая воспроизводимость – обеспечение на уровне источников данных, например, гарантии на распределения.
3. Решена ли проблема? Как бы ДА, но много НО. Не стоит полагаться на модель. Если шаги препроцессинга сложны – версионриовать от дельно от сырых.
На что еще посмотреть? Feature Stores – обеспечение гарантий.
Работа Yandex.DataSphere – единый пул железа, одна среда, одни источники данных, сохранение промежуточных шагов по состоянию и диску, сохраняем не только модель, а весь контекст обучения.
Предиктивный компонент. Потребитель отправляет запрос (телефон, куку, емайл). Данные отправляем на матчинг и процесс предобработки (граф связей). База фич занимает 2.6ТБ. к Фичам применяется предиктор. Сервис поточный. Отказоустойчивость обеспечивается дубликатом сервера. Обновление фичей через HDFS proxy. Хранение фичей в древовидной файловой системе с 3 уровнями вложенностями, сжатые текстовые файлы. По железу: e5v3 cpu, 128gb ram, hdd 4x800gb ssd.
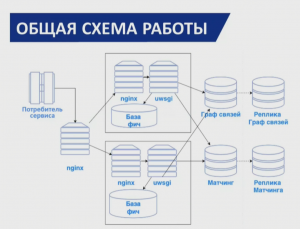
Капла-архитектура и потоковая обработка данных. Данные могут устаревать очень быстро. Реагирование на момент появления этих данных. Возраст данных влияет на монетизации. Сильная актуальность данных – клиент приобретает устройство, оформляют кредит, цена данных очень высока. Банку важно понимать, что есть потенциальный клиент и дать ему наилучшее предложение. Второй пример – доверительный платеж. Преимущества системы – низкие затраты на разработку, решение всех необходимых задач по доставке кода, единая точка управления продуктами, единый пункт отказоустойчивости и контроля.
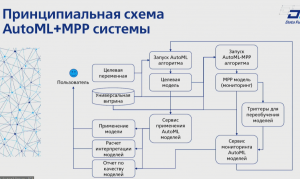
Запрос на AutoML. Бизнес не может существовать без анализа своей клиентской базы и рынка. Данные (обишрный периметр данных), Операционная эффективность (автомл для быстрого построения моделей), корректность (точность и актаульность).
Что такое AutoML – процесс автоматизации сквозного процесса применения машинного обучения к задачам реального мира. Быстрая разработка простых решений, не уступающая моделям, созданным вручную. Запрос на мл модели постоянно растет, что приводит к использованию алгоритмов.
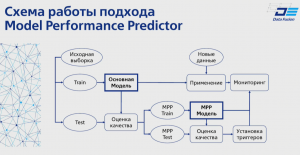
MPP – подход построения вспомогательной мониторинговой модели для предсказания качества работы основной. Целевая переменная MPP – метрика качества работы основной модели.