В целях масштабирование и совершенствования аналитических решений ведущие игроки используют концепцию MLOps
- Цифровой дизайн
- Big Data технологии
- Сервисная модель —MLOps
Компоненты DevOps + модели
- Репозиторий — Модели + алгоритмы
- Развёртывание — Модель + Контейнер+ ETL
- Автотесты — Модели + Витрина
- Мониторинг — Расписание
- Обратная связь — Группа реагирования
Способы сокращения среднего времени разработки и внедрений решений
| Инструменты | Потенциальный эффект |
| Конвейер MLOps с автоматизацией | Производительность рабочей группы по машинному обучению - 50% |
| Надлежащий процесс разработки моделей машинного обучения, соответствующий agile – принципам и существующим ролям | Срок вывода новой модели - 25% |
| Обучение Data scientist-ов эффективным методам разработки ПО | Срок вывода нового релиза на рынок – 50% |
Выводы:
- Продуктом, создающим ценность для бизнеса является не только модель но и технологическое решение по её применению в бизнес процессе;
- Сервисная модель MLOps появляются в ответ на рост аппетита к ИИ;
- Ключевые цели MLOps для решения возрастающего потока задач – сокращение TTM, Повышение фиктивности команд, масштабируемость;
- Сервисная модель определяют ключевые компетенции, участвующие в разработке моделей и типовой процесс взаимодействия между ними;
- Инструментарий для моделирования работает в связке с CI/CD Инфраструктурой, адаптированный для внедрения моделей
- Файл не выбран.
ВОСПРОИЗВОДИМОСТЬ MLOps
Data Science is not Data Programming
- Нет этапа проектирования, итеративный процесс
- Важно не только конечный результат но и промежуточные шаги
- Воспроизводимость зависит не только от кода но и от данных
Важно повторить результаты при переходе:
- От прототипа к экспериментам
- От экспериментов к сервису
Типы воспроизводимости
- Вычислительная: код, среда
Mlflow – платформа для управления ML разработкой
- Эмпирическая: данные, способ их получения
Data Version Control
- Статистическая: параметры, пороговые значения
Воспроизводимости в Yandex.DataSphere добиваются с помощью объединения контуров разработки, экспериментов и эксплуатации
RPEDICT, Mail.Group
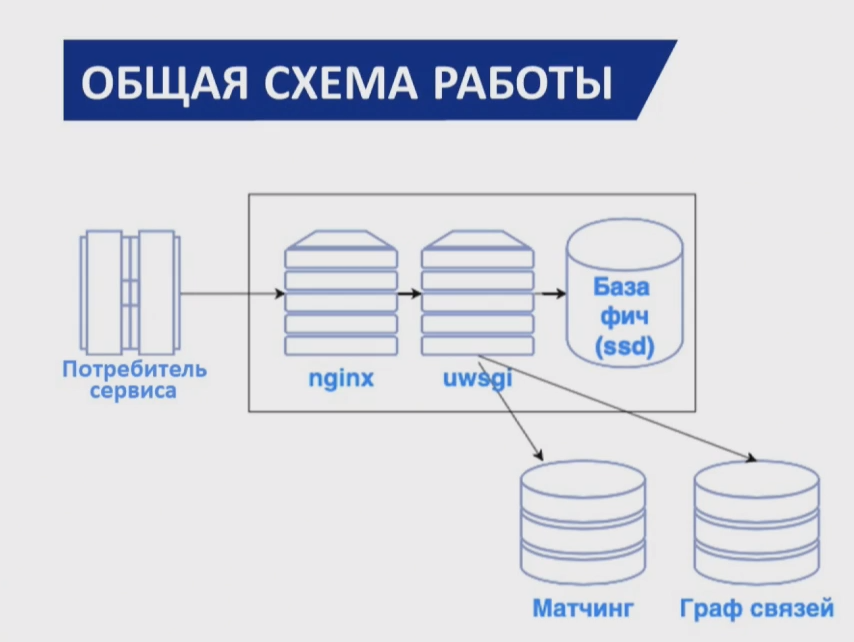
Data Engeener, Tele2
Чем больше времени проходит с момента появления данных, тем потенциальная выгода от их использования сильно уменьшается.
Каппа - архитектура и потоковая обработка данных появились в связи с необходимостью гарантировать минимальную задержку.
Преимущества системы:
- Чрезвычайно низкие затраты на разработку;
- Решение всех необходимых задач по доставке кода;
- Единая точка управления продуктами;
- Единый пункт отказоустойчивости и контроля.
Для поддержки потоковых приложений мы хотели сохранить тот же способ автоматизации, единую точку контроля, что и для пакетных приложений, а также минимизировать количество используемых ресурсов.
Концепт
- Автоматизация потоковых приложений не должна отличаться от автоматизации пакетных приложений
- Сборка Scala приложений на «лету» из репозитория.
MPP подход в AutoML задачах
Эволюция построения моделей. Запрос на AutoML.
- Данные
- Операционная эффективность
- Корректность
- Консистентность
Автоматическое машинное обучение – процесс автоматизации сквозного процесса применения машинного обучения к задачам реального мира
Дает преимущество получения более простых решений, более быстрого создания таких решений и моделей, которые не уступают построенным вручную.
Мотивация использования МРР подхода
Запрос на ML-модели постоянно растет, что приводит к использованию AutoML – алгоритмов. Но нельзя говорить о полноценном AutoML без автоматического мониторинга построенных моделей.
- Задержка отклика реализации целевой переменной
- Нерегулярность обновления данных
- Поддержание стабильности и консистенции построенных моделей
- Операционная эффективность построения и обновления моделей
Model Performance Predictor – подход построения вспомогательной, мониторинговой, модели для предсказания качества работы основной.
Целевая переменная – метрика качества работы основной модели.
- Универсальность
- Простота построения
- Фокус на конкурентную модель
- Оперативность
Модель оценивает совместное распределение факторов с точки зрения работы основной модели, реагируя не на величину изменений в распределениях отдельных слоёв данных, а на общий сдвиг качества работы основной модели.